|
|
|
Vediamo come funziona l'algoritmo basandoci su un esempio di rete formata da 5 nodi e 6 rami, come nella figura sotto riportata.
La rete e' puramente esemplificativa: non differenziamo tra host e routers, subnets e link. I nodi della nostra rete devono semplicemente essere in grado di replicare i pacchetti. Ogni nodo e' identificato dal proprio indirizzo (nel caso A, B, C, D ed E) e la tabella di routing avra' una voce per ciascuno degli indirizzi. Per semplicita' assumiamo che tutti i link siano simmetrici.
Supponiamo di inizializzare la rete alimentando tutti i nodi contemporanemente, quello che viene definito dagli specialisti un "cold start". In questo stato, ciascuno dei nodi e' caratterizzato unicamente da una conoscenza locale, che significa che ciascun nodo conosce il proprio indirizzo, ma ignora totalmente la topologia della rete. La tabella di routing sara' quindi minima, caratterizzata da una singola voce, quella del nodo stesso. Ad esempio, la tabella di A sara' :
Il nodo A riassume la tabella in un vettore, chiamato "distance vector" che, nel caso, sara' composto dall' unico elemento A = 0. Il vettore verra' quindi replicato a tutti i nodi vicini, nel caso B e D che possono quindi accrescere la loro conoscenza della rete. Vediamo, in dettaglio, B. Prima di ricevere il vettore da A, la sua tabella di routing sara' formata da un unica voce :
Dopo aver ricevuto, attraverso il link 1, il distance vector A = 0, B aggiorna tutte le distanze aggiungendo loro il costo del link locale, che assumiamo essere uguale a 1 e trasforma quindi il messaggio da A = 0 ad A = 1. Quindi confronta l'informazione del vettore con le voci presenti nella sua tabella di routing, rileva che il nodo A e' ancora sconosciuto e, di conseguenza, aggiorna la tabella di routing che diventa :
B puo' ora preparare il proprio distance vector (B = 0, A = 1) e inviarlo attraverso i suoi link locali, ossia 1, 2 e 4. Nel frattempo, anche il nodo D avra' ricevuto il messaggio iniziale da A e avra' aggiornato la propria tabella in :
e potra' quindi inviare il proprio distance vector (D = 0, A =1) sui link 3 e 6. Il messaggio proveniente da B sara' ricevuto da A, C ed E, mentre quello da D sara' ricevuto da A ed E. Supponiamo, per comodita', che il messaggio da B sia ricevuto prima. Ricevendo il messaggio attraverso il link 1, A aggiornera' le distanze a B = 1 ed A = 2. Poiche' quest'ultima e' maggiore della voce relativa al link locale, la tabella di A verra' aggiornata con la sola voce relativa al nodo B. Infine, ricevendo il messaggio attraverso il link 3, verra' inserita anche l'informazione relativa al nodo D. La nuova tabella sara' :
A sua volta, il nodo C ricevera' il vettore B = 0, A = 1 attraverso il link 2, e aggiornera' la propria tabella:
Il nodo E ricevera' il vettore B = 0, A = 1 attraverso il link 4 e aggiornera' la propria tabella:
quindi ricevera' il vettore D = 0, A = 1 attraverso il link 6, lo aggiornera' in D = 1, A = 2, osservando che la voce D dovra' essere inserita in tabella mentre la distanza da A attraverso il link 6 e' esattamente uguale a quella gia' presente in tabella attraverso il link 4. Assumeremo che in questo caso la tabella non venga modificata e che quindi diventi :
Dopo che A, C ed E avranno quindi calcolato le loro nuove tabelle, invieranno sui loro link locali i propri distance vectors Da A : A = 0, B = 1, D = 1, attraverso i link 1 e 3 Da C : C = 0, B = 1, A = 2, attraverso i link 2 e 5 Da E : E = 0, B = 1, A = 2, D = 1 attraverso i link 4, 5 e 6 che causeranno un aggiornamento alle tabelle di B, D ed E in :
B, D ed E possono quindi preparare i nuovi vettori : Da B : B = 0, A = 1, D = 2, C = 1, E = 1, attraverso i link 1, 3 e 4 Da D : D = 0, A = 1, B = 2, E = 1, attraverso i link 3 e 6 Da E : E = 0, B = 1, A = 2, D = 1, C = 1, attraverso i link 4, 5 e 6 che saranno ricevuti da A, C e D che aggiorneranno quindi le loro tabelle :
A questo punto, l'algoritmo converge. A, C e D prepareranno dei nuovi vettori e li invieranno attraverso i link locali, ma la ricezione di questi ultimi non causeranno ulteriori aggiornamenti alle tabelle di B, D ed E. E quindi possibile affermare che, attraverso queste operazioni di calcolo distribuito, i nodi hanno rilevato la topologia della rete
Di seguito e' riportato un grafico che illustra un esempio delle tabelle di routing e dei distance vector di due generici routers :
Ipotizziamo che, per un qualsiasi motivo, il ramo 1 della rete vista in precedenza, cada o diventi indisponibile. I due nodi A e B, che sono i terminali del ramo in esame, rilevano il guasto ed aggiornano di conseguenza le loro tabelle di routing, rilevando che il link1 assume ora un costo "infinito" e che tutti i nodi precedentemente raggiungibili attraverso tale link, sono ora collocati ad una distanza infinita. Le nuove tabelle saranno :
Ma i nodi A e B prepareranno ed invieranno i nuovi vettori : Da A : A = 0, B = inf, D = 1, C = inf, E = inf, attraverso il link 3 Da B : B = 0, A = inf, D = inf, C = 1, E = 1, attraverso i link 2 e 4 Il vettore inviato da A sara' ricevuto da D, che aggiornera' le distanze aggiungendo il costo del ramo 3 in : A = 1, B = inf, D = 2, C = inf, E = inf Gli elementi di questo vettore saranno quindi confrontati con le voci presenti nella tabella di D; verra' rilevato che tutte le distanze del vettore sono maggiori o al limite uguali a quelle memorizzate, ma che il ramo 3, attraverso il quale e' stato ricevuto il vettore, e' esattamente quello utilizzato per raggiugere B. Quindi, la voce per il nodo B dovrebbe essere aggiornata per riflettere il nuovo valore. La tabella di D diventa :
In modo simile, anche C ed E aggiorneranno le proprie tabelle :
Questi 3 nodi, prepareranno ed invieranno quindi i nuovi distance vector : Da D : D = 0, A = 1, B = inf, E = 1, C = 2, attraverso i link 3 e 6 Da C : C = 0, B = 1, A = inf, E = 1, D = 2, attraverso i link 2 e 5 Da E : E = 0, B = 1, A = inf, D = 1, C = 1, attraverso i link 4, 5 e 6 Questi messaggi causeranno un aggiornamento alle tabelle dei nodi A, B, D ed E in :
e, dopo gli aggiornamenti, i nodi invieranno i nuovi vettori : Da A : A = 0, B = inf, D = 1, C = 3, E = 2, attraverso il link 3 Da B : B = 0, A = inf, D = 2, C = 1, D = 1, attraverso i link 2 e 4 Da D : D = 0, A = 1, B = 2, E = 1, C = 2, attraverso i link 3 e 6 Da E : E = 0, B = 1, A = 2, D = 1, C = 1, attraverso i link 4, 5 e 6 che causeranno l'aggiornamento delle tabelle dei nodi A, B e C
I nodi A, B e C prepareranno ed invieranno i loro nuovi vettori, ma questi non produrranno nessun ulteriore aggiornamento delle tabelle di routing. I nuovi percorsi sono definitivamente stati calcolati e la connettivita' globale e' stata quindi ripristinata.
In pratica, quello che succede nel caso di un malfunzionamento su un link, e' di seguito riassunto:
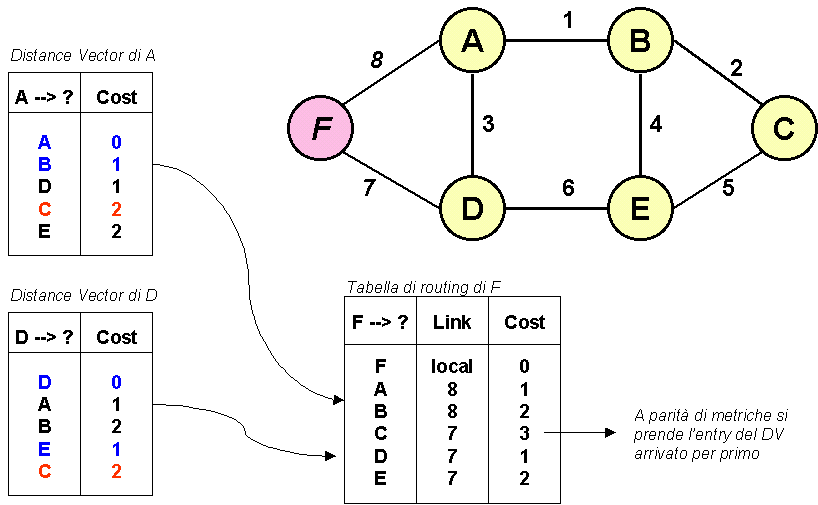
Vediamo un esempio di fusione di distance vector:
Negli esempi precedenti abbiamo assunto che il costo dei singoli links fosse pari ad 1; questo puo' non essere sempre il caso : alcuni rami possono essere piu' lenti o piu' costosi rispetto ad altri. Ipotizziamo, nella rete di esempio, che il ramo 5 abbia un costo 10, mentre tutti gli altri continuino ad avere un costo pari ad 1. Concentriamoci sui percorsi dei vari nodi verso il nodo C. In condizioni di stabilita', dopo un cold start, noi troveremmo la seguente situazione :
Supponiamo ora che il ramo 2 diventi indisponibile; il problema viene immediatamente rilevato dal nodo B, per cui la tabella vista in precedenza, per un breve periodo diventera' :
Supponiamo inoltre che, immediatamente prima che B spedisca il proprio distance vector ai nodi vicini, A invii il proprio vettore a B e D. Il messaggio non avra' effetti su D, poiche' la distanza corrisponde alla tabella. Viceversa B, informato da A, incrementera' il costo 1 alla distanza 2 per C, e notera' che il costo 3 e' inferiore rispetto al costo infinito in tabella. Di conseguenza, aggiornera' la propria tabella ad indicare che C e' ora raggiungibile attraverso il link 1 ad un costo 3 ed informera' di questo i suoi nodi vicini A ed E. Poiche' questo avverra' attraverso i links 1 e 4 che A ed E utilizzano rispettivamente per raggiungere C, questi aggiorneranno le rispettive tabelle. La situazione, vista dal nodo C, sara' dunque :
Si puo' notare come la tabella adesso includa un loop : i pacchetti verso C raggiungono B e quindi rimbalzano avanti e indietro tra A e B sino a quando viene a cessare il loro "time to live". Questo fenomeno e' chiamato effetto rimbalzo (bouncing effect). Verra' a cessare solo quando la rete convergera' con delle coerenti tabelle di routing. Se, nel frattempo, C invia il proprio vettore attraverso il link 5, il nodo E aggiungera' il costo 10 a 0, rilevera' che questo costo totale e' piu' elevato che il valore corrente in tabella e ignorera' il messaggio. Ora, se A ed E invieranno i loro nuovi vettori, questi verranno ricevuti dai nodi B e D. La nuova tabella sara' :
Dopo che B ha trasmesso il proprio vettore, il costo della voce A per il nodo C incrementera' a 6. Il nodo A inviera' questo nuovo costo a B e D. La tabella risultante sara' :
A questo punto, i messaggi inviati tramite C sono ancora ignorati da E, in quanto il costo della voce E per il nodo C e' ancora inferiore a 10. Infatti, ad ogni nuovo scambio di messaggi, la distanza verso il nodo C sara' incrementata di 2 per ciascuno dei nodi A, B, D ed E. Al successivo step quindi avremo :
Il successivo messaggio da B causera' un aggiornamento a 10 del costo di A, che trasmettera' il nuovo valore a B e D che, a loro volta, aggiorneranno entrambi il proprio costo a 11. Il nodo B inviera' il costo 11 ad A ed E, per cui la tabella aggiornata sara' :
Questa volta, se E riceve un messaggio da C, lo considera e, dopo aver aggiornato la tabella, converge al nuovo valore.
Finalmente, i calcoli sono stati completati. Ma sono stati necessari numerosi step, in quanto la rete deve incrementare le varie distanze gradualmente. Poiche' uno step di messaggi incrementa il costo di 2 unita', si sono resi necessari 5 scambi di messaggi per raggiungere il valore di 10, necessario per il successivo step. Da notare che questo e' un processo random, il cui termine puo' variare in relazione all'ordine di trasmissione dei messaggi dai vari siti. Inoltre negli gli stati intermedi, in situazione di loop, si possono verificare accumuli di pacchetti con conseguenti congestioni dei link corrispondenti, che possono causare delle perdite ai pacchetti stessi, messaggi di routing compresi. Questo si ripercuotera' in maggiori ritardi nella convergenza allo stato stabile.
Consideriamo nuovamente la rete vista precedentemente. Abbiamo visto come, nel caso di indisponibilita' di un ramo, vengano identificati nuovi cammini. Supponiamo che, oltre che il link 1, anche il link 6 cada o cessi di funzionare. Si puo' osservare immediatamente che i nodi A e D diventano del tutto isolati dai nodi B, C ed E. Abbandoniamo questi nodi al loro destino e concentriamoci a quanto succede tra A e D. Il nodo D rileva il nuovo guasto ed aggiorna di conseguenza la propria tabella :
Se D ha l'opportunita' di inviare immediatamente il proprio distance vector , A aggiornera' immediatamente la propria tabella rilevando che tutti i nodi, ad eccezione di D, sono diventati irraggiungibili: l'algoritmo converge. Ma se invece A ha l'opportunita' di inviare prima il suo ultimo distance vector : Da A : A = 0, B = 3, D = 1, C = 3, E = 2 allora la tabella di D verra' aggiornata in :
Si e' quindi inizializzato un loop, come nel precedente esempio. Ma, a differenza di questo, poiche' B, C ed E sono effettivamente isolati non vi e' alcuna possibilita' di convergere naturalmente ad uno stato stabile. Ad ogni scambio, quindi, le distanze B, C ed E verranno incrementate di 2 unita'. Questo processo e' conosciuto come conteggio all'infinito (counting to infinity) e puo' essere terminato solo attraverso una convenzione sulla rappresentazione di infinito a distanze molto grandi (piu' grandi della lunghezza del peggior possibile percorso nella rete). Quando la distanza raggiunge questo valore, l'entry nella tabella di routing viene considerata infinitamente distante e, di conseguenza, irraggiungibile. Come nel caso precedente, si puo' verificare che lo stato intermedio della rete durante il processo e' molto confuso; loops, congestioni e perdite di pacchetti sono effetti classici. Tuttavia, e' altresi' rilevabile che, in assenza di ulteriori modifiche alla tipologia della rete, questa convergera' lentamente al nuovo stato.
L'effetto bouncing e il lungo tempo richiesto per il count to infinity sono effetti indesiderabili dei protocolli distance vectors. Tra le numerose tecniche studiate per minimizzare questi effetti, si distinguono lo "split horizon" ed il "triggered updates" implementati nel protocollo RIP. Lo Split Horizon si basa su una precauzione molto semplice: se il nodo A sta instradando pacchetti per la destinazione X attraverso il nodo B, non ha senso, per B, tentare di raggiungere X attraverso A. Cosi' non ha senso per A annunciare a B che X e' una "corta distanza" da A. Rispetto alla versione originale del protocollo distance vector, la modifica e' minima: invece di diffondere lo stesso distance vector su tutti i links in uscita, i nodi invieranno differenti versioni di questo messaggio, per tenere conto del fatto che alcune destinazioni sono attualmente instradate attraverso i suddetti links in uscita. Split horizon prevede 2 variazioni. Nella forma piu' semplice, i nodi semplicemente omettono nei loro messaggi qualsiasi informazione circa le destinazioni instradate sul link. Questa strategia si affida sia su cammini mai annunciati che su vecchi annunci che vengono meno in seguito a meccanismi di timeout. La forma "Split horizon with poisonous reverse" e' piu' aggressiva: i nodi includono tutte le destinazioni nel messaggio distance vector, ma configurano le corrispondenti distanze ad infinito se la destinazione e' instradata sul link. Questo immediatamente eliminera' 2 hop-loops. Si puo' provare con relativa semplicita' come questa tecnica avrebbe immediatamente eliminato il count to infinity dell'esempio precedente . Comunque, split horizon non e' in grado di proteggere contro tutte le forme di loop.
Sinora abbiamo evitato di occuparci di un caso particolare: quando inviare il distance vector ad un nodo vicino. Questa decisione e', in effetti, un compromesso tra una serie di fattori: tempestivita' dell'informazione, necessita' di attendere un completo set di aggiornamenti prima di prendere decisioni, resistenza alla perdita di pacchetti, monitoraggio dei nodi vicini e cosi' via. Parecchie implementazioni del protocollo distance vector, tra cui RIP, si affidano sull'invio regolare dei messaggi distance vector attraverso i nodi, sia per il monitoraggio dei nodi vicini che per la correzione dei pacchetti persi. Ad ogni entry della tabella viene associato un timer. Se l'informazione non viene rinfrescata con la ricezione di un nuovo pacchetto prima della scadenza del timer, si assume che il nodo vicino, relativo a quella route, si sia probabilmente guastato e si fissa la distanza verso quella destinazione ad infinito. Il timer deve essere fissato in modo che sia molto piu' lungo del periodo di trasmissione dell'informazione. Sarebbe irresponsabile fissare come irraggiungibile una distanza solo perche' un pacchetto e' andato perso. RIP, per esempio, suggerisce che questo timer dovrebbe essere 6 volte l'intervallo di trasmissione, in modo che la route rimanga operativa se viene ricevuto almeno un pacchetto su sei. Inoltre, va tenuto in considerazione il carico della rete provocato dalla ripetizione degli avvisi, per cui il periodo non puo' essere troppo corto. Un lungo periodo tra le emissioni ha, comunque, una conseguenza fastidiosa: se avviene una modifica alla rete subito dopo un'emissione, si dovra' attendere sino alla fine del periodo per segnalare la modifica ai vicini. La procedura, conosciuta come "triggered updates", e' un tentativo di incrementare la sensibilita' del protocollo, richiedendo i nodi ai quali inviare i messaggi, non appena questi verificano un cambiamento alle tabelle di routing, senza dover attendere la fine del periodo. Questa procedura certamente aumenta la velocita' di convergenza; nella documentazione RIP si sostiene, tra l'altro, che inviando triggering updates abbastanza velocemente, le corrette informazioni si propagheranno immediatamente, evitando cosi' il maggior numero di loops intermedi.
Il fine degli algoritmi di routing e' quello di calcolare le routes con il percorso piu' breve verso una destinazione; si tratta di un problema matematico ben conosciuto. I protocolli distance vector sono basati sull'algoritmo di Bellman-Ford, che e' una versione distribuita di un algoritmo molto semplice per la ricerca del percorso piu' breve. Di seguito e' riportata la versione centralizzata:
|