|
|
I protocolli di tipo Link State sono basati sul concetto di "mappa distribuita": tutti i nodi posseggono una copia della mappa della rete, che viene regolarmente aggiornata. In seguito esamineremo come la mappa sia in effetti rappresentata da un database, come avvengono gli aggiornamenti ai nodi della rete, perche' questi aggiornamenti devono essere sicuri ed infine perche' alcuni protocolli della famiglia Link State vengono denominati "shortest path first" (SPF)
DATABASE LINK STATE E LSP Il principio alla base dell'instradamento di tipo Link State e' molto semplice : Invece di calcolare i percorsi migliori in modo distribuito, tutti i nodi mantengono una copia intera della mappa della rete ed eseguono un calcolo completo dei migliori percorsi da questa mappa locale. La mappa e' contenuta in un database, dove ciascun record rappresenta un link nella rete. Ad esempio la rete sotto riportata
sara' rappresentata dal seguente database:
Ciascun record e' inserito da una stazione responsabile per questo e che contiene un identificatore di interfaccia, il numero di link nel nostro caso, e le informazioni che descrivono lo stato del link: la destinazione e la distanza o metrica. Con queste informazioni ogni nodo puo' facilmente calcolare il percorso piu' breve da se' stesso a tutti gli altri nodi. Con la velocita' degli attuali computers, e' necessario solo un brevissimo tempo, tipicamente una frazione di secondo se la rete non e' molto estesa, per calcolare tali percorsi. Poiche' tutti i nodi contengono lo stesso database ed eseguono lo stesso algoritmo di route-generation, i percorsi sono coerenti e non si verificano loops. Ad esempio, se noi inviamo un pacchetto dal nodo A al nodo C nella rete riportata in precedenza, ci baseremo sui calcoli tra i nodi A e B. Il nodo A puo' rilevare, tramite il database, che il percorso piu' corto verso C passa attraverso il nodo B e quindi invia il pacchetto sul link numero 1 . Il nodo B, a sua volta, inviera' il pacchetto sul link numero 2. I pacchetti inviati da un router e che, ricevuti dai vari router della rete, permettono la costruzione della mappa della rete, sono detti Link State Packet (LSP). Il Link State Packet (LSP) contiene:
Un LSP viene generato periodicamente, oppure quando viene rilevata una variazione nella topologia locale (adiacenze), ossia :
Il LSP è trasmesso in flooding su tutti i link del router e tutti i router del dominio di routing ricevono il LSP. All'atto del ricevimento di un LSP il router compie le seguenti azioni:
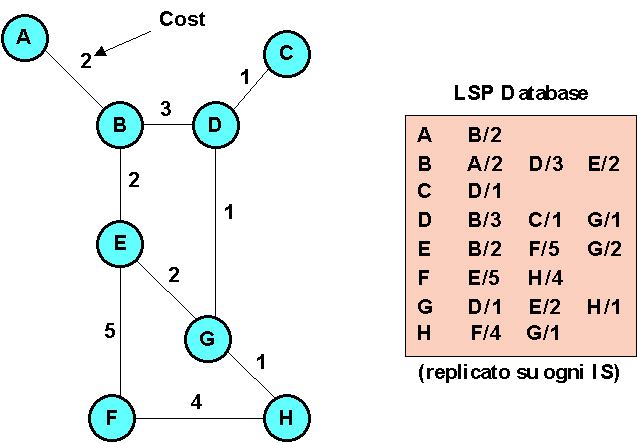
Vediamo, infine, un ulteriore esempio di una rete e dei relativi database (replicati per ogni nodo):
Il fine di un protocollo di routing e' quello di adattare i routers alle modifiche della rete. Questo puo' essere fatto solo se il database viene aggiornato dopo ogni modifica dello stato del link. Ad esempio, ipotizziamo che, nella rete vista in precedenza, il link 1 diventi indisponibile. I nodi A e B rileveranno il cambio di stato su questo link e dovranno quindi aggiornare, di conseguenza, i corrispondenti records nel database e inviarli a tutti gli altri nodi. Il protocollo da utilizzare per questo scopo dovrebbe essere veloce ed affidabile, ossia avere le caratteristiche del protocollo "flooding". Subito dopo aver rilevato la caduta del link 1, il nodo A invia al nodo D il seguente messaggio di aggiornamento sul link 3 :
il nodo D ritrasmettera' immediatamente il messaggio al nodo E sul link numero 6, per essere infine inviato a B sul link 4 e a C sul link 5. In effetti il messaggio sara' lievemente piu' complesso di quanto esposto. Se non venissero prese sufficienti precauzioni, potrebbe verificarsi che un vecchio messaggio torni indietro e comprometta il database. Per questo, ogni messaggio contiene un avviso dell'ora o un numero del messaggio che abilita il nodo in ricezione a distinguere le vecchie e le nuove informazioni. L'algoritmo flooding puo' quindi essere espresso molto semplicemente nel modo seguente:
In questo algoritmo l'operazione di diffusione causera' la trasmissione del messaggio su tutte le interfacce ad eccezione di quelle di arrivo. Se assumiamo che il numero iniziale associato con il record del database era 1, il messaggio inviato da A sara':
D aggiornera' il proprio database e diffondera' il messaggio ad E che, a sua volta, aggiornera' il proprio database e inviera' il messaggio a B e C, i quali aggiorneranno i loro records e tenteranno di inviare, a loro volta, i messaggi a C e B rispettivamente. Quando riceveranno il secondo messaggio C e B rileveranno che il numero e' uguale a quello nel database e quindi non ritrasmetteranno oltre. L'algoritmo flooding si ferma qui. Nello stesso tempo, B avra' trasmesso il nuovo stato del link 1 a C ed E :
Il protocollo provvedera' ad aggiornare D e, di seguito, A e, quindi, saranno calcolati i nuovi percorsi. Il database dopo il flooding si presentera' dunque cosi' :
Poiche' l'obbiettivo e' quello di mantenere la rete operativa per un un tempo molto lungo, puo' accadere che la sequenza dei numeri possa eccedere il numero di bit assegnati per la loro codifica nei pacchetti o nei record del database; normalmente i protocolli usano una numerazione circolare a 32 bit ma necessitano di una specifica convenzione al fine di definire con certezza quando un numero X e' piu grande di un numero Y.
Consideriamo il caso, cosi' come abbiamo fatto per i protocolli distance vector, di un secondo link failure, anche in questo caso sul link 6. Per riassumere la situazione, osservando la rete in esame, i links "caduti" sono rispettivamente l' 1 e il 6. Questo ha un'interessante conseguenza nel caso del link state. La caduta del link 6 viene rilevata dai nodi D ed E, ma entrambi saranno in grado di distribuire la nuova informazione solo ai loro vicini connessi. Dopo l'esecuzione dell'algoritmo di flooding, si avranno cosi' 2 versioni del database: la rete verra' divisa in due parti non connesse, A e D da un lato mentre B, C ed E dall'altro vedranno valori differenti. Questo e' il database visto da A e D:
mentre questo e' il database visto da B, C ed E:
Questo non e' molto importante, poiche' qualsiasi route da A e D verso B, C o E avverra' attraverso un link con una metrica infinita. A e D rileveranno che B, C ed E sono irraggiungibili e altrettanto faranno B, C ed E nei confronti di A e D. Infatti, essi saranno in grado di calcolare questo nuovo stato di routing immediatamente dopo aver ricevuto il nuovo link state senza alcun rischio di impegnarsi in procedure di conteggio all'infinito, tipiche degli algoritmi distance vector. Se le 2 parti rimangono isolate per un lungo periodo, le 2 versioni del database possono evolvere indipendentemente (per esempio il link2 puo' diventare disconnesso). Il database visto da B, C ed E allora diventerebbe:
mentre il database visto da A e D non cambierebbe. Anche questo non e' molto importante: B, C ed E calcoleranno i percorsi corretti per scambiarsi pacchetti tra loro, mentre A e D rimarranno sconnessi. Ma vediamo cosa succede quando uno dei 2 links viene resettato, riconnettendo di fatto le 2 parti. Distribuire semplicemente l'informazione sul nuovo link potrebbe non essere sufficiente. Supponiamo che sia il link 1 a tornare operativo; i records che lo descrivono verranno corretti in entrambe le parti della rete, ma i records che descrivono i link 2 e 6 saranno ancora incoerenti. Stabilire la connettivita' tra 2 nodi richiede qualcosa in piu' che semplicemente inviare un record di database. E' necessario garantire che le 2 parti allineino i propri database. Questa procedura e' chiamata "bringing up adjacencies" in OSPF, uno dei principali protocolli di routing basato sulla tecnologia link state.. L'allineamento dei due database e' facilitato dall'esistenza degli identificatori di link e dai numeri di versione. Le 2 parti devono sincronizzare i loro database e mantenere solo le versioni piu' aggiornate di ciascun record, ad esempio, per ciascun link, il record con il numero piu' grande. Tuttavia, implementare un "merge" scambiando copie complete, appare piuttosto inefficiente; nel caso che piu' record siano simili nelle 2 copie, non esiste la necessita' di inviarli. OSPF risolve questo problema definendo pacchetti di descrizione del database, che contengono solamente gli identificatori dei link ed i corrispondenti numeri di versione. Nella prima fase della procedura di sincronizzazione, entrambi i routers invieranno una completa descrizione dei loro records in una sequenza di pacchetti di descrizione. Dopo la ricezione di questi pacchetti, confronteranno i numeri di sequenza con quelli presenti nel proprio database e prepareranno una lista di "record interessati", ad esempio quando il numero remoto e' maggiore del numero locale o quando l'identificatore di link non e' presente nel database locale . Nella seconda fase, ciascun router richiedera' al proprio vicino una copia di tali record tramite dei pacchetti cosidetti di "link state request". Come conseguenza della sincronizzazione, molti record verranno
aggiornati e verranno inviati ai nodi vicini, utilizzando la normale procedura
flooding.
L'intera idea dei protocolli di routing "link state" e' di mantenere una copia sincronizzata del database sullo stato dei link in tutti i nodi della rete. Abbiamo visto che e' essenziale che tutte le copie siano identiche, altrimenti la coerenza degli instradamenti non potrebbe essere garantita. In realta', ci sono degli intervalli di transizione, durante i quali, alcuni nodi potrebbero essere piu' aggiornati rispetto ad altri; quello che succede, tipicamente, dopo un failure ad un link. Tuttavia, la procedura di flooding propaghera' velocemente gli aggiornamenti a tutti i nodi della rete. Nel 1983, Radia Perlman dimostro' l'esigenza di proteggere attivamente i database distribuiti contro possibili corruzioni quali anomalie nelle procedure di flooding o di sincronizzazione, il mantenimento di record ormai superati nel database, errori di memoria o tentativi di corruzione esterna volontaria. Sfruttando questo lavoro, OSPF implementa una serie di protezioni contro questi pericoli, di seguito elencate :
Abbiamo visto, nella pagina dedicata ai protocolli distance vector che, al fine di calcolare il percorso piu' breve, questi si basano sull'algoritmo di Bellman-Ford che e' un algoritmo piuttosto semplice ma non molto efficiente. La proposta di un algoritmo piu' veloce ed efficiente fu avanzata da E.W. Dijkstra con il suo "shortest path first". L'algoritmo SPF calcola il percorso piu' breve tra un nodo sorgente ed un altro nodo della rete, definendo:
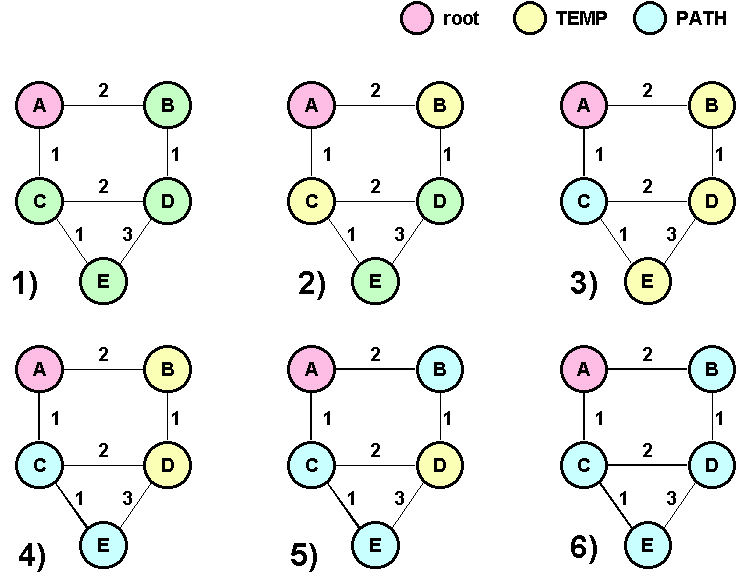
L'algoritmo e' il seguente : 1. Si inserisce il nodo root in PATH 2. Si inseriscono tutti i nodi vicini del precedente in TEMP 3. Si prende il nodo N con il percorso più piccolo in TEMP e lo si promuove in PATH 4. Per ogni vicino V del nodo N promosso:
Principi di funzionamento dell’algoritmo
Un esempio
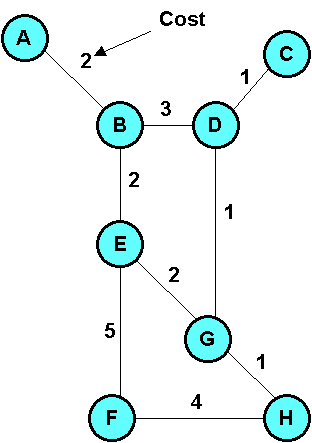
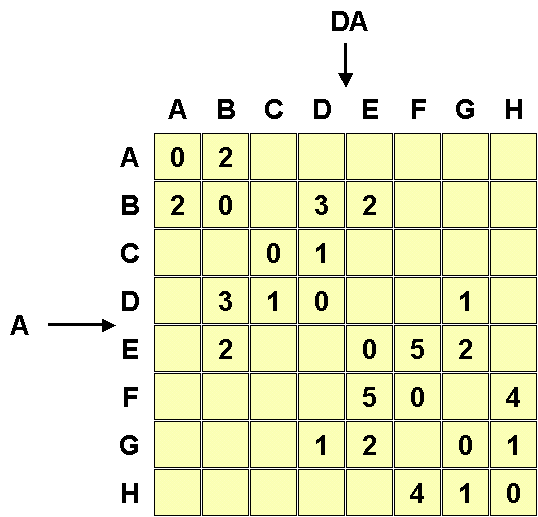
Al fine di applicare correttamente l'algoritmo di Dijkstra, la rappresentazione piu' appropriata e' quella tabellare, che immediatamente "rende" visibile lo stato della rete. Nell'esempio sotto illustrato si riporta una rete con la tabella relativa al database:
Si puo' facilmente dimostrare che il numero totale dei percorsi che saranno considerati e' uguale al numero dei link nella rete. SPF converge in 0(M logM) iterazioni, mentre l'algoritmo di Bellman-Ford converge in 0(N M) iterazioni, dove M e' il numero dei link ed N e' il numero dei nodi, generalmente dello stesso ordine di grandezza del numero dei link. Per reti di grandi dimensioni con molti links, la differenza e' quindi sostanziale. Abbiamo cosi' visto le ragioni del nome "OSPF" (Open Short Path First) - perche' i nodi si aspettano di supportare l'algoritmo SPF ed inoltre perche' la specifica fu sviluppata in modo "aperto" dall'IETF.
|