|
|
OSPF e' l'acronimo di Open Shortest Path First; questo protocollo di routing si basa sulla tecnologia Link State, a differenza di RIP che e' invece basato sull'algoritmo distance vector ed il suo progetto ha seguito la teoria di questa tecnologia: esistono infatti un database distribuito, una procedura di flooding, una definizione di adjacency e records speciali per routes esterne. OSPF utilizza il concetto di gerarchia, per cui permette di gestire reti di dimensioni notevoli. Un AS viene suddiviso in aree, le quali contengono un gruppo di reti contigue. Questo garantisce un basso utilizzo di CPU e memoria. OSPF e' un protocollo sviluppato dalla IETF, e' utilizzato su Internet ed e' il protocollo raccomandato dalla IAB in sostituzione di RIP. OSPF e' stato progettato per :
Vediamo di estendere con maggior dettaglio questi concetti:
Molto spesso, nelle reti moderne, gli host IP sono connessi a reti locali, ad esempio una rete Ethernet. Se si applica strettamente il modello Link State, dovremmo descrivere, attraverso un record di link state la relazione tra ciascun host ed il router. OSPF permette una semplificazione, basata sul modello "subnet" di IP. Poiche' tutti gli hosts della rete appartengono ad una singola sottorete IP, e' sufficiente inviare un messaggio sul link tra il router e la sottorete. Nella terminologia OSPF, questa e' una speciale variante di "router link" chiamata "link to a stub network". Il link verso un vicino e' identificato dall'indirizzo IP del vicino stesso, mentre quello verso una "stub network" e' identificato dal suo numero di rete o sottorete.
Le reti locali, come Ethernet o Token Ring, offrono 2 tipi di servizi:
Il problema da risolvere e' il seguente: dati N routers su una rete locale, e' possibile stabilire che esistono N*(N-1)/2 adiacenze, tali che ogni router deve quindi inviare N-1 messaggi verso gli altri routers vicini piu' uno verso la rete (stub network) per un totale di N*N messaggi. OSPF prova a ridurre a solo N adiacenze designando uno dei router (Designed Router o DR) in modo tale che i rimanenti routers stabiliscano adiacenze solo con il router designato.
Il primo passo e' eleggere il router designato. Questa elezione e' incorporata nella procedura "Hello". Dopo l'elezione, gli altri routers porteranno le proprie adiacenze verso il router designato o sincronizzeranno il proprio database. La presenza del router designato serve inoltre per :
Tuttavia, se il DR cade, tutti i routers apparirebbero disconnessi dalla rete, sebbene questa sia, a tutti gli effetti, ancora operativa. Risulta quindi indispensabile eleggere al piu' presto un nuovo DR. OSPF ovvia questo problema, con l'elezione di un "Backup Designed Router o BPR", contemporaneamente all'elezione del DR. Tutti i routers creeranno quindi le proprie adiacenze con entrambi i routers DR e BDR; se il DR cade, l'anomalia verra' immediatamente rilevata dal protocollo Hello, il BDR diventera' immediatamente DR ed un nuovo BDR verra' eletto. Tutti i routers stabiliranno un adiacenza con il nuovo BDR.
Reti come X.25, Frame Relay e ATM, sebbene con profonde differenze, in termini di velocita' e servizi, sono accumunate da un aspetto: sono tutte quante reti non broadcast. Ci sono 2 modi di utilizzare questi tipi di reti:
OSPF utilizza questa seconda scelta e quindi le informazioni di routing verranno inviate solo attraverso tali routers. Il fatto di avere un DR non modifica di fatto il routing; i circuiti virtuali saranno stabiliti tra qualsiasi coppia di router ed i pacchetti IP saranno inviati direttamente su questi circuiti virtuali. Tuttavia, questi circuiti verranno stabiliti solo "su domanda". I soli circuiti che verranno utilizzati quasi permanentemente dagli aggiornamenti sono quelli che collegano i routers ordinari al DR e al BDR. La differenza principale tra reti broadcast e non-broadcast deriva dall'assenza di qualsiasi facility multicast nelle reti non-broadcast. Tutti i pacchetti di advertisment dovranno essere inviati in modalita' point-to-point. I pacchetti Hello, utilizzati per il processo di elezione prevederanno una lista di tutti i router sulla rete non-broadcast. Il DR invia a tutti una LSA spedendo una copia separata del pacchetto a ciascun router. Quando un router diffonde una LSA, lo fa inviando una copia al DR ed un'altra al BDR.
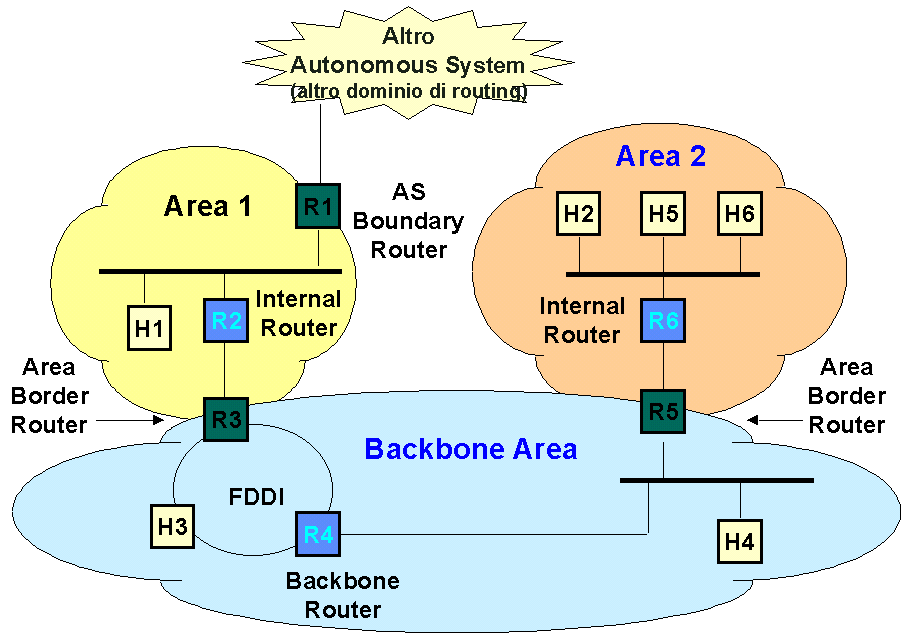
Il formato del database, la durata del calcolo della route ed il volume dei messaggi aumenta con l'aumentare della rete. Se questa diventa molto grande, tutti questi fattori diventano eccessivi; la memoria richiesta e' troppa, i calcoli richiedono lunghi tempi ed il carico della rete non e' piu' sopportabile. La risposta a questo problema e' il "routing gerarchico" ossia la suddivisione della rete in un set di parti indipendenti connesse attraverso un "backbone". In OSPF le parti indipendenti sono chiamate aree e la parte superiore e' chiamata "Backbone area". Ciascuna area si comporta come una rete indipendente; il database include solo lo stato dei link dell'area, il protocollo di flooding si ferma ai confini dell'area ed i routers calcolano solo le routes all'interno dell'area. Il costo del protocollo di routing e' cosi' proporzionale al formato dell'area e non a quello della rete. Allo scopo di connettere l'intera rete, alcuni routers appartengono a piu' aree - tipicamente a un'area a basso livello e all'area di backbone. Questi routers sono chiamati "area-border routers" (ABR): ci deve essere perlomeno un ABR in ciascun area, per connetterla al backbone. Gli ABR mantengono numerosi database, uno per ciascuna area alla quale appartengono ed ogni area include un set di sottoreti IP. Oltre agli ABR, possiamo distinguere ancora 2 tipologie di router:
Cosi' come per i router, anche per le aree ed in funzione della destinazione del traffico, oltre alla gia' citata backbone area, possiamo distinguere ulteriori tre tipologie:
Nella seguente figura, viene illustrato un esempio di rete composta da 3 aree (delle quali una e' l'area di backbone) e da una serie di router interni, ABR e ASBR:
|